Game Engine Project
This is a team project for CSCI522 Game Engine Design, one of my most exciting projects. Me and my teammate enriched the original engine called “Prime Engine” provided by Professor Artjoms Kovalovs. For the purpose of exercise, the engine provided by the professor is very simple and crude so we need to fullfill it by programming the sub engines.That’s said, the bulk of the work was upgrading the engine.
Main project of the class is a milestone project finished by me and my teammate. We chose to focus on the physics part. We programmed the physics engine from scratch and fullfilled it with collision, gravity, rolling effect and friction. We also considered about the further development of collision system of the high speed object collision. So the engine could deal with stuff like photon shot from blasters or flying bullets.
Other works done with the engine
In the class, I fullfill the engine with character interaction system, which allows the characters move between waypoints and have interaction with other objects such as aiming and shooting.
To optimize engine performance, I also added Axis-Aligned-Bounding-Box to the objects so that the engine could cull out the objects out of the camera frustum. As can be seen from the video, the framerate can be massively improved with the culling system.
The improved engine can also simulate the wind effect. Wind source was added to the constant buffer and a 2nd UV-set was added to vertex shader to control the wind effect. The wind sourse was added to the soldiers and the camera. The lamps shows how wind effect is displayed on objects.
Hope you like my project.
PEACE.
 语义分割效果示例
语义分割效果示例
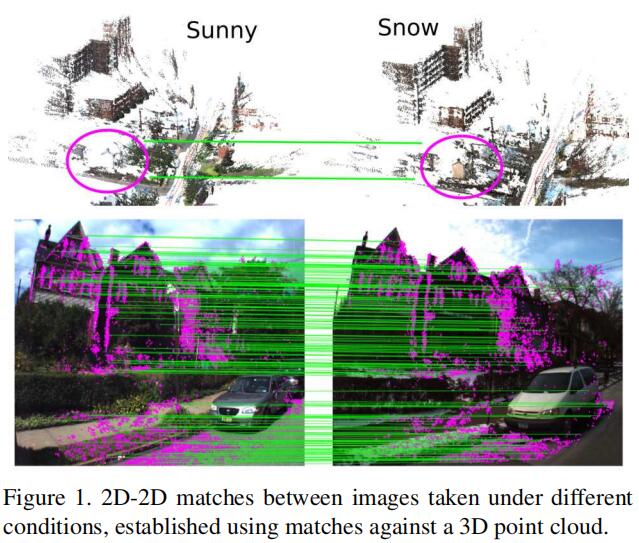 2D-2D匹配和对应关系的建立
2D-2D匹配和对应关系的建立